
Background
A user reported unsatisfactory system throughput for NocoBase via a GitHub issue. Given our product’s rapid iteration, the team is currently prioritizing system functionality improvements, with less focus on specific optimizations for performance. However, as NocoBase moves into production and expands its user base, performance issues are emerging. It is imperative for us to intensify our focus and initiate optimization efforts.
Certainly, for a product like NocoBase, real-world application scenarios tend to be complex, and there’s significant variation in user habits. Performance optimization necessitates specific, phased analyses for different scenarios. It’s not feasible to comprehensively address all issues in a single optimization round.
This optimization round focuses on providing an initial assessment of the system’s server-side API performance, followed by targeted foundational improvements.
Performance testing
Explanation
NocoBase utilizes the underlying framework of Koa + Sequelize. We have designed several test scenarios to use as benchmarks for comparative analysis:
- Koa + Sequelize: This represents the foundational framework, reflecting the theoretical optimum, although real-world scenarios might introduce some compromises.
- Koa + @nocobase/database: @nocobase/database is a Sequelize-based abstraction layer for database operations.
- Koa + @nocobase/resourcer: @nocobase/resourcer functions as the routing and dispatching layer.
- Koa + @nocobase/server: @nocobase/server serves as the NocoBase server.
- Koa + Nocobase: This is the complete NocoBase program, incorporating built-in plugins.
This performance test is not a simulation of a production environment for exhaustive stress testing. Instead, it focuses on layered testing to compare data and identify the primary factors affecting API performance. The tests were primarily conducted on my personal computer with the following specifications:
- Operating System: MacOS 14.0
- CPU: 10 cores
- Memory: 32GB
- Database: PostgreSQL (Docker, latest version)
- NocoBase Execution:
yarn start -d
The tested API endpoint is /api/users:list, equivalent to executing select ... limit 20 and count statements on the users table. The specific code can be referenced here.
Each test scenario was evaluated using the command wrk -t20 -c20 -d1m.
Koa + Sequelize
RPS: 6938.71
> $ wrk -t20 -c20 -d1m http://localhost:13020/
Running 1m test @ http://localhost:13020/
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 2.91ms 0.88ms 38.10ms 97.01%
Req/Sec 348.52 30.22 434.00 84.53%
416831 requests in 1.00m, 141.52MB read
Requests/sec: 6938.71
Transfer/sec: 2.36MB
Databse CPU > 100%
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
80393e7580c1 postgres 125.63% 196.7MiB / 7.748GiB 2.48% 11.6GB / 15.8GB 76.4MB / 2.81GB 11
PostgreSQL typically utilizes only one CPU core, indicating that the performance bottleneck lies within the database.
Koa + @nocobase/database
RPS: 5487.29
> $ wrk -t20 -c20 -d1m http://localhost:13010/
Running 1m test @ http://localhost:13010/
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 3.66ms 795.89us 32.80ms 91.85%
Req/Sec 275.53 21.87 434.00 82.60%
329784 requests in 1.00m, 121.71MB read
Requests/sec: 5487.29
Transfer/sec: 2.03MB
Database CPU > 100%
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
80393e7580c1 postgres 102.99% 197.7MiB / 7.748GiB 2.49% 12.3GB / 16.6GB 76.5MB / 2.82GB 11
Performance has declined somewhat, but it is acceptable, and the database is generally running at its capacity.
Koa + @nocobase/resourcer
RPS: 4787.94
> $ wrk -t20 -c20 -d1m 'http://localhost:13040/api/users:list'
Running 1m test @ http://localhost:13040/api/users
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 4.20ms 0.92ms 30.97ms 88.29%
Req/Sec 240.48 18.01 333.00 80.79%
287757 requests in 1.00m, 120.47MB read
Requests/sec: 4787.94
Transfer/sec: 2.00MB
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
80393e7580c1 postgres 87.72% 197.3MiB / 7.748GiB 2.49% 12.6GB / 17GB 76.5MB / 2.82GB 11
Performance has further degraded, and the database has not reached its full capacity. We will analyze the reasons later.
Koa + @nocobase/server
RPS: 2285.86
> $ wrk -t20 -c20 -d1m 'http://localhost:13030/api/users:list'
Running 1m test @ http://localhost:13030/api/users:list
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 8.80ms 2.05ms 93.25ms 97.23%
Req/Sec 114.80 9.27 300.00 93.35%
137358 requests in 1.00m, 87.90MB read
Requests/sec: 2285.86
Transfer/sec: 1.46MB
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
80393e7580c1 postgres 47.82% 197.5MiB / 7.748GiB 2.49% 13.2GB / 17.7GB 76.9MB / 3.15GB 11
Comparing the test data with Koa + @nocobase/resourcer, there is approximately a 50% reduction in performance, indicating that the primary performance bottleneck has shifted from the database to the program itself.
Nocobase
RPS: 580.48
> $ wrk -t20 -c20 -d1m 'http://localhost:13000/api/users:list?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VySWQiOjEsImlhdCI6MTcwMTY3MjA3MCwiZXhwIjoxNzAyMjc2ODcwfQ.ISmvJ7cc2XhlNO3xB6O2gndvwKS2Xs71Fo2bXuRpmfg'
Running 1m test @ http://localhost:13000/api/users:list?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VySWQiOjEsImlhdCI6MTcwMTY3MjA3MCwiZXhwIjoxNzAyMjc2ODcwfQ.ISmvJ7cc2XhlNO3xB6O2gndvwKS2Xs71Fo2bXuRpmfg
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 34.44ms 3.85ms 97.95ms 85.18%
Req/Sec 29.03 3.94 50.00 85.04%
34886 requests in 1.00m, 26.25MB read
Requests/sec: 580.48
Transfer/sec: 447.27KB
The comprehensive performance of NocoBase has significantly declined, as anticipated before testing. This is because the interfaces traverse numerous plugin middlewares, involving authentication, permission checks, and database queries. Notably, caching has not been implemented up to this point, making it a key focus for optimization in the current phase.
Code Analysis and Optimization
Sequelize -> database -> resourcer
Transitioning from the underlying Sequelize to the database, and then to the resourcer, although each layer incurs some performance overhead, it remains acceptable for a single process. This is mainly due to additional encapsulation of code logic. As the current optimization focus is not on achieving a complete solution in one go, this part will be maintained as is for now, and any necessary adjustments will be addressed separately in the future.
resourcer -> server
Transitioning from the resourcer to the server, the performance degradation exceeds half, indicating a definite issue in this area. Therefore, let’s start the analysis here. The server introduces additional application-level middleware compared to the resourcer (refer to helper.ts). Upon reviewing the code, most logic seems relatively straightforward, with no apparent areas significantly impacting performance. Consequently, I have decided to collect data related to the time consumption of middleware to gain further insights.
perf_hooks
NodeJS provides performance testing APIs through perf_hooks. These APIs offer a richer set of metrics beyond simple execution time calculations. In our context, the focus remains on scrutinizing the time spent in each middleware. By utilizing perf_hooks.createHistogram to construct histograms, we can execute stress tests, meticulously logging the execution times of each middleware. This approach enables us to derive key statistics such as minimum, maximum, and median execution times over the stress testing period. For instance:
{
"i18n": {
"count": 12455,
"min": 1875,
"max": 927231,
"mean": 4867.227137695704,
"exceeds": 0,
"stddev": 10258.399954791737,
"percentiles": {
"0": 1875,
"50": 3250,
"75": 5372,
"100": 926720
}
}
}
Upon sorting the results, two middleware components that notably impact performance stand out: logging and i18n.
Logging
By default, NocoBase outputs logs to both files and the terminal simultaneously. Referring to the Node.js documentation on process I/O,
Warning: Synchronous writes block the event loop until the write has completed.
In my testing environment, both of these outputs are likely synchronous, and since there is logging for every request and response, it inevitably has some impact on performance. Considering that interface logs are essential, we will maintain the current configuration for now. However, in a production environment, it’s common to only retain file logs. Therefore, in future tests, we can consider disabling terminal logs to reduce some performance overhead. In production, adjusting log levels as needed is also a viable option.
i18n
The i18n middleware, responsible for managing localized resources, showed significant time consumption, with the main bottleneck identified in the following code line:
const i18n = ctx.app.i18n.cloneInstance({ initImmediate: false });
The current approach of cloning an i18n instance for isolating language resources in different requests is time-consuming. To optimize, a singleton pattern based on language can be implemented, allowing the reuse of existing instances for the same language instead of reloading them for each request.
server -> NocoBase
Transition from a simple server to the complete NocoBase, there’s a significant performance drop. As mentioned earlier, the full NocoBase includes numerous built-in plugins, introducing many route-layer middlewares, including authentication and permissions. Following the methods discussed earlier, we used perf_hooks to measure the time spent in these middlewares. The results highlight the two most impactful middlewares and their main execution logic:
authManager.middleware- Middleware for user authentication- Check if the user token is in the blacklist.
- Retrieve the currently used authentication method.
- Obtain user information based on the authentication method.
acl.setCurrentRole- Middleware for setting role information in the permission module- Retrieve associated role information based on the current user ID and set the user’s role.
Both of these middlewares perform database queries in their primary logic for each request. To address this, we are introducing caching.
Caching strategy
Storage
NocoBase currently employs both in-memory and Redis caching. For relatively static data, like system authentication methods, we store it in memory. Data related to user information follows the default storage configuration, allowing users to opt for Redis as the default storage method.
On-Demand Caching + Hook Updates
Data such as authentication methods, user information, and roles typically fall into the category of read-intensive and write-minimal. We implement an on-demand caching strategy, where the first request triggers a database query, and the results are cached. Subsequent requests use the cached results. To ensure data consistency, we introduce hooks to listen for any database changes and synchronize them with the cache.
Bloom Filter
For token blacklist queries, where we need to compare user tokens with those on the blacklist, on-demand caching is not suitable. Instead, during program startup, we preload the blacklist tokens into the cache. To save memory space, we employ a Bloom filter for caching the blacklist. The Bloom filter accurately determines if a value is not present, with a probability of misjudging the existence of a value. Initially, the Bloom filter checks whether a user token is in the blacklist. If the Bloom filter indicates existence, we perform a secondary database query for accuracy.
LRU
NocoBase’s in-memory cache defaults to using the Least Recently Used (LRU) strategy for cache eviction. Users can configure cache policies, such as setting an upper limit on cache space. For Redis users, custom cache strategies like LRU or LFU can be configured as needed.
Other Optimizations
In addition to the middleware optimizations mentioned earlier, some middleware, such as db2resource and ACLMiddleware, also impact performance. To further analyze potential performance bottlenecks, and since there are currently no straightforward optimization tasks, we plan to enable the inspector to examine the system’s CPU profile during runtime.
# Enable inspector
NODE_ARGS=--inspect yarn start
By continuously sending requests to the API using wrk and capturing the CPU profile in Chrome DevTools over a specific duration, we can obtain results similar to the following.
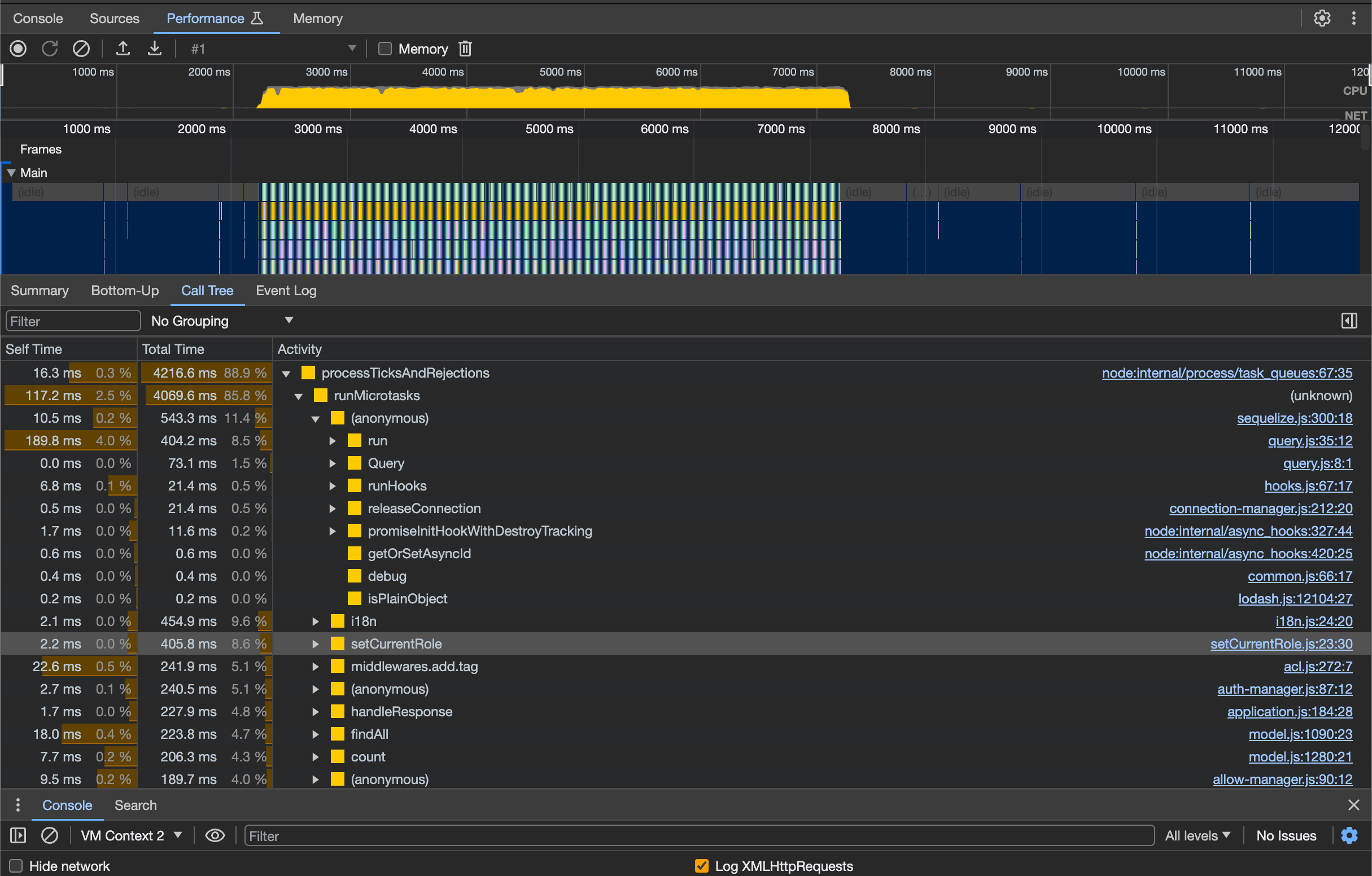
Upon inspecting the profile, we identified that certain logic in the db2resource for parsing routes, such as the use of pathToRegexp, has a noticeable impact on performance, explaining the further degradation in performance at the routing layer observed in previous tests. In the ACLMiddleware, operations related to permission handling, like miniMatch, also showed longer execution times. For these aspects, we have implemented some preliminary optimizations, such as caching variables for repetitive calculations. More extensive optimizations will be addressed in future iterations.
Summary
Optimization Results
In this optimization effort, we focused on:
- Use variables for caching time-consuming operations in middleware, such as
i18ninstance creation and permission checks. - Introducing appropriate caching mechanisms for middleware operations that involve frequent database queries.
Additionally, we recommend adjusting the logging output level and method in the production environment based on requirements to mitigate the impact of log printing on API performance.
After implementing these optimizations, retesting the complete NocoBase application revealed significant improvements in API performance.
> $ wrk -c20 -t20 -d1m 'http://localhost:13000/api/users:list?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VySWQiOjEsImlhdCI6MTcwMTY5NzU5MCwiZXhwIjoxNzAyMzAyMzkwfQ.Fs7ccoBKi2F2MPOCO5kpJHTH_mnVhqkFVQmlBzgBza0'
Running 1m test @ http://localhost:13000/api/users:list?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VySWQiOjEsImlhdCI6MTcwMTY5NzU5MCwiZXhwIjoxNzAyMzAyMzkwfQ.Fs7ccoBKi2F2MPOCO5kpJHTH_mnVhqkFVQmlBzgBza0
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 9.60ms 2.62ms 103.80ms 96.32%
Req/Sec 105.44 11.62 393.00 83.66%
126047 requests in 1.00m, 60.10MB read
Non-2xx or 3xx responses: 2
Requests/sec: 2097.31
Transfer/sec: 1.00MB
Continuous Optimization
The optimization process in this round has certain limitations:
On one hand, we only tested simple requests. In real business scenarios, aspects like filtering, variable parsing, complex transactions, etc., may present additional performance challenges that require further optimization.
On the other hand, we focused on optimizing the parts that significantly impact performance, leaving room for improvement in other areas.
In the future, we will continue to optimize the performance of NocoBase. If you encounter performance issues in your usage, please feel free to provide specific cases for analysis and optimization. Your feedback will be valuable in addressing real-world usage scenarios.