
背景
有用户通过 GitHub issue 反馈 NocoBase 的系统吞吐量表现不佳。作为一个快速迭代的产品,现阶段团队成员的工作重点可能在于完善系统功能,过去对于系统性能方面确实没有进行专门的优化。随着 NocoBase 面向更多的用户,逐渐步入生产环境,系统各方面的性能问题也逐渐暴露出来,需要我们提高重视程度,着手进行优化。
当然,对于 NocoBase 这样一个产品,实际的应用场景通常比较复杂,不同用户的使用习惯差异也比较大,性能问题的优化需要对不同的场景具体分析,分阶段进行,不可能在一次优化中面面俱到,解决所有问题。
本次调研和优化的主要目标是对系统服务端接口的性能有一个初步的测算和评估,并针对性地进行一些通用的、基础的优化工作。
性能测试
说明
由于 NocoBase 使用的底层框架是 Koa + Sequelize,我们设置以下几组测试,将数据作为基准来参考对比。
- Koa + Sequelize - 底层框架,理论最优情况,实际肯定会有打折。
- Koa + @nocobase/database - @nocobase/database 是基于 Sequelize 实现的,对数据库操作的上层封装。
- Koa + @nocobase/resourcer - @nocobase/resourcer 是路由分发层
- Koa + @nocobase/server - @nocobase/server 是 NocoBase 服务端
- Koa + Nocobase - 包含内置插件的完整 NocoBase 程序
本次性能测试并不是模拟生产环境,做一次完整的压测。而是通过分层测试,进行数据对比,来找到目前主要影响接口性能的部分。测试主要在我的个人电脑上进行,使用的测试工具为 wrk, 主要参数如下:
- 系统: MacOS 14.0
- CPU: 10core
- 内存: 32GB
- 数据库: PostgreSQL (Docker 最新版本)
- NocoBase 运行方式:
yarn start -d
测试的接口为 /api/users:list, 即相当于在 users 表上执行 select ... limit 20 和 count 语句。具体代码可以参考 benchmark.
对每组测试执行 wrk -t20 -c20 -d1m.
Koa + Sequelize
RPS: 6938.71
> $ wrk -t20 -c20 -d1m http://localhost:13020/
Running 1m test @ http://localhost:13020/
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 2.91ms 0.88ms 38.10ms 97.01%
Req/Sec 348.52 30.22 434.00 84.53%
416831 requests in 1.00m, 141.52MB read
Requests/sec: 6938.71
Transfer/sec: 2.36MB
数据库 CPU > 100%
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
80393e7580c1 postgres 125.63% 196.7MiB / 7.748GiB 2.48% 11.6GB / 15.8GB 76.4MB / 2.81GB 11
PosgreSQL 通常只使用一个 CPU 核心,说明此时性能瓶颈在数据库。
Koa + @nocobase/database
RPS: 5487.29
> $ wrk -t20 -c20 -d1m http://localhost:13010/
Running 1m test @ http://localhost:13010/
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 3.66ms 795.89us 32.80ms 91.85%
Req/Sec 275.53 21.87 434.00 82.60%
329784 requests in 1.00m, 121.71MB read
Requests/sec: 5487.29
Transfer/sec: 2.03MB
数据库 CPU > 100%
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
80393e7580c1 postgres 102.99% 197.7MiB / 7.748GiB 2.49% 12.3GB / 16.6GB 76.5MB / 2.82GB 11
性能有所下降,但可以接受,数据库也基本可以跑满。
Koa + @nocobase/resourcer
RPS: 4787.94
> $ wrk -t20 -c20 -d1m 'http://localhost:13040/api/users:list'
Running 1m test @ http://localhost:13040/api/users
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 4.20ms 0.92ms 30.97ms 88.29%
Req/Sec 240.48 18.01 333.00 80.79%
287757 requests in 1.00m, 120.47MB read
Requests/sec: 4787.94
Transfer/sec: 2.00MB
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
80393e7580c1 postgres 87.72% 197.3MiB / 7.748GiB 2.49% 12.6GB / 17GB 76.5MB / 2.82GB 11
性能进一步损耗,数据库也没有跑满。原因我们后面再分析。
Koa + @nocobase/server
RPS: 2285.86
> $ wrk -t20 -c20 -d1m 'http://localhost:13030/api/users:list'
Running 1m test @ http://localhost:13030/api/users:list
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 8.80ms 2.05ms 93.25ms 97.23%
Req/Sec 114.80 9.27 300.00 93.35%
137358 requests in 1.00m, 87.90MB read
Requests/sec: 2285.86
Transfer/sec: 1.46MB
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
80393e7580c1 postgres 47.82% 197.5MiB / 7.748GiB 2.49% 13.2GB / 17.7GB 76.9MB / 3.15GB 11
对比 Koa + @nocobase/resourcer 的测试数据,性能损耗一半左右,主要的性能瓶颈已经从数据库转移到程序本身。
Nocobase
RPS: 580.48
> $ wrk -t20 -c20 -d1m 'http://localhost:13000/api/users:list?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VySWQiOjEsImlhdCI6MTcwMTY3MjA3MCwiZXhwIjoxNzAyMjc2ODcwfQ.ISmvJ7cc2XhlNO3xB6O2gndvwKS2Xs71Fo2bXuRpmfg'
Running 1m test @ http://localhost:13000/api/users:list?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VySWQiOjEsImlhdCI6MTcwMTY3MjA3MCwiZXhwIjoxNzAyMjc2ODcwfQ.ISmvJ7cc2XhlNO3xB6O2gndvwKS2Xs71Fo2bXuRpmfg
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 34.44ms 3.85ms 97.95ms 85.18%
Req/Sec 29.03 3.94 50.00 85.04%
34886 requests in 1.00m, 26.25MB read
Requests/sec: 580.48
Transfer/sec: 447.27KB
完整的 NocoBase 性能表现下降很多。这其实是测试前我们大致可以预料到的结果,因为接口要经过很多插件中间件,包括认证、权限等判断和处理,其中涉及到一些查库的操作,之前我们都没有进行缓存,这也是我们目前阶段要优化的重点。
代码分析和优化
Sequelize -> database -> resourcer
从底层的 Sequelize 到 database, 再到 resourcer, 虽然每一层的性能都有损耗,但是对于单进程,表现尚可接受。这里主要也是多了一些代码逻辑的封装,本次优化也不是追求一步到位,所以这部分暂时维持现状,后面有需要再拎出来单独优化。
resourcer -> server
从 resourcer 到 server, 性能损耗超过一半,说明这里肯定存在问题,所以先从这里着手分析。server 主要比 resourcer 多了一些应用层的中间件(参考)。从代码上,逻辑大多比较简单,看不出特别影响性能的地方,于是我决定收集一下跟中间件的耗时相关的数据。
perf_hooks
NodeJS 提供了跟性能测试相关的 API: perf_hooks, 相比于单纯的计算耗时,可以收集到一些其他的指标。不过我们这里还是主要看一些各个中间件的耗时,可以利用 perf_hooks.createHistogram 创建一个直方图,通过执行压测程序,并记录每个中间件的执行时间,就可以统计出在压测时间内,中间件执行时间的最小值、最大值、中位数等数据。类似:
{
"i18n": {
"count": 12455,
"min": 1875,
"max": 927231,
"mean": 4867.227137695704,
"exceeds": 0,
"stddev": 10258.399954791737,
"percentiles": {
"0": 1875,
"50": 3250,
"75": 5372,
"100": 926720
}
}
}
通过对统计结果排序,我发现了两个比较影响性能的中间件:日志和 i18n.
日志
默认情况下,NocoBase 会同时向文件和终端输出日志。根据 node 文档的说明,A note on process I/O,
Warning: Synchronous writes block the event loop until the write has completed.
在我的测试环境中,这两种输出应该都是同步的,而接口的请求和响应都会有日志输出,不可避免会对性能造成一定的影响。考虑到接口日志是不可或缺的,暂时维持现状。不过在生产环境,我们通常只需要保留文件日志,所以在后续测试的时候可以关闭终端日志来降低一部分性能的损耗。在生产环境中,也可以按需调整日志级别。
i18n
i18n 中间件主要是本地化资源相关的一些逻辑,经过进一步测试发现,主要耗时的部分集中在这行代码:
const i18n = ctx.app.i18n.cloneInstance({ initImmediate: false });
这里每次 clone 一个 i18n 实例来隔离不同请求使用的语言资源,但是观察下来每次都执行这个操作是比较耗时的。这里的解决方案是按照不同的语言,改成一个单例实现,这样在语言相同的情况下就可以使用已有的实例,而不是每次都重新加载。
server -> NocoBase
从单纯的 server 到完整的 NocoBase, 性能表现大打折扣。原因我们之前也提到,完整 NocoBase 包含了很多内置插件,插件增加了很多路由层中间件,包含了认证、权限等。参考前面的方法,我们同样先用 perf_hooks 来统计比较一下这些中间件的耗时。结果显示影响最大的两个中间件及其主要执行逻辑是:
authManager.middleware- 用户认证模块的鉴权中间件- 判断用户 token 是否在黑名单中
- 获取当前使用的认证方式
- 根据认证方式获取用户信息
acl.setCurrentRole- 权限模块的设置角色信息的中间件- 根据当前用户 ID 获取关联角色信息,并设置用户角色
上面两个中间件的主要执行逻辑都涉及到查询数据库的操作,而且每个请求都会执行,对于这个这部分我们目前的解决方案是增加缓存。
缓存策略
存储
目前 NocoBase 内置的缓存存储有内存和 redis. 对于类似系统认证方式这样相对固定的数据,我们会存储到内存中。跟用户信息相关的数据,会按照用户 ID, 跟随系统默认的存储方式进行存储,如果用户配置了 redis 作为默认的存储方式,就会存储到 redis 中。
按需缓存 + hook 更新
对于上述的认证方式、用户信息、角色等数据通常都属于读多写少的类型,缓存采用按需缓存的策略,即第一次请求的时候查询数据库并缓存查询结果,下一次请求的时候使用缓存结果。同时为了确保数据的一致性,增加 hook 监听数据库的数据变动,来同步更新缓存。
布隆过滤器
对于 token 黑名单的查询,因为我们需要将用户 token 和黑名单中的 token 进行比对,所以不能采用按需缓存的策略来缓存某个 token,而是应该在程序启动的时候将黑名单的 token 预加载到缓存。为了节省内存空间,我们用布隆过滤器来缓存黑名单,布隆过滤器的特点是可以准确判断某个值不存在,有一定概率误判某个值存在。首先用布隆过滤器判断用户 token 是否在黑名单中,不在的话则可以直接返回结果,如果布隆过滤器返回存在,我们可以再一步查询数据库来保证准确性。
LRU
NocoBase 的内存缓存默认使用 LRU 策略来淘汰缓存,可以通过配置来限制缓存空间上限。如果使用 redis,则可以自行配置缓存策略,如 LRU 或 LFU 等。
其他优化
在前面对中间件耗时的测试中,除了上面提到的对性能影响比较严重的中间件,还有一些中间件对性能也有影响,比如 db2resource, ACLMiddleware. 为了进一步分析系统可能还存在哪些比较影响性能的部分,现阶段还有没有一些相对简单的优化工作可以完成,我们通过开启 inspector 来查看系统运行时的 CPU profile.
# 开启 inspector
NODE_ARGS=--inspect yarn start
使用 wrk 向接口持续发起请求,然后利用 Chrome dev tools 抓取一段时间内程序运行的 CPU Profile, 我们可以得到类似这样的结果。
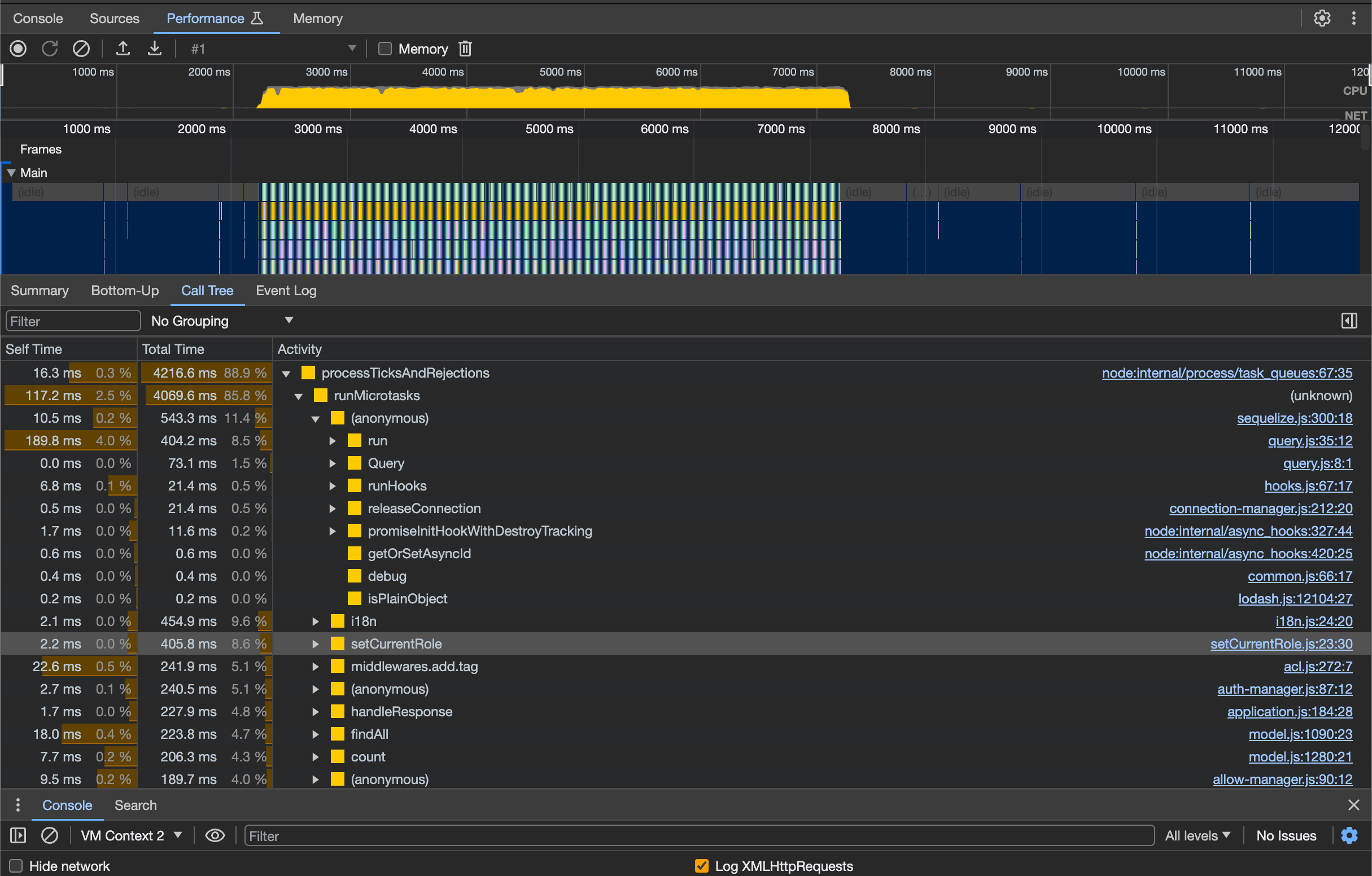
通过观察 Profile 我们发现 db2resource 中解析路由的一些逻辑对性能有一定影响,比如用到 pathToRegexp 是比较消耗 CPU 资源的操作,这也解释了前面测试中,在路由层上性能有进一步损耗的问题。在 ACLMiddleware 中也发现权限处理相关的操作,比如 miniMatch, 执行时间比较长。对于这部分我们暂时做了一些简单的优化,比如对一些重复的计算做了变量缓存,更进一步的优化则放到以后。
总结
优化结果
我们本次优化主要有:
- 对中间件中耗时较长的逻辑,如 i18n 实例创建、权限判断,使用变量缓存。
- 对中间件中频繁查询数据库的逻辑,使用适当的缓存。
同时我们建议在生产环境根据需要调整日志的输出级别和方式,以降低日志打印对接口性能的影响。
经过上述优化,对完整的 NocoBase 应用重新进行测试,可以看到接口的性能表现有较大的提升。
> $ wrk -c20 -t20 -d1m 'http://localhost:13000/api/users:list?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VySWQiOjEsImlhdCI6MTcwMTY5NzU5MCwiZXhwIjoxNzAyMzAyMzkwfQ.Fs7ccoBKi2F2MPOCO5kpJHTH_mnVhqkFVQmlBzgBza0'
Running 1m test @ http://localhost:13000/api/users:list?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VySWQiOjEsImlhdCI6MTcwMTY5NzU5MCwiZXhwIjoxNzAyMzAyMzkwfQ.Fs7ccoBKi2F2MPOCO5kpJHTH_mnVhqkFVQmlBzgBza0
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 9.60ms 2.62ms 103.80ms 96.32%
Req/Sec 105.44 11.62 393.00 83.66%
126047 requests in 1.00m, 60.10MB read
Non-2xx or 3xx responses: 2
Requests/sec: 2097.31
Transfer/sec: 1.00MB
持续优化
本次优化过程也存在一些局限性:
一方面是只对简单的接口请求做了测试,在真实业务场景下,如过滤、变量解析、复杂事务,还有更多性能问题需要我们去优化;
另一方面是只对影响性能比较严重的部分进行了优化,还存在一些优化空间。
在未来我们会对 NocoBase 的性能做持续的优化,如果你在使用的过程中,遭遇性能问题,欢迎向我们反馈具体的 case, 以方便我们对实际的使用场景做分析和优化。