
この記事はLeandro Martinsによって作成され、最初にBuilding an AI Assistant with Langflow and AstraDB: From Architecture to Integration with NocoBaseに公開されました。
はじめに
この記事の目的は、NocoBase、LangFlow、VectorDB を統合したAIアシスタントの作成方法を紹介することです。基盤として、NocoBase で開発中のシステムを使用します。このシステムはアーキテクチャデータを管理するためのもので、AIアシスタントを追加して、アプリケーション、APIカタログ、ソリューションデザイン、ストーリー などのデータから洞察を生成します。
この記事では、以下の技術を使用します:
- NocoBase、PostgreSQL、Docker(この記事ではインストール方法を紹介します)。
- LangFlow(ローカルで実行、Docker経由でインストール可能)。
- ベクトルデータベース(AstraDB のアカウントを作成し、この記事ではAstraDBをベクトルデータベースとして使用します)。
アーキテクチャ概要
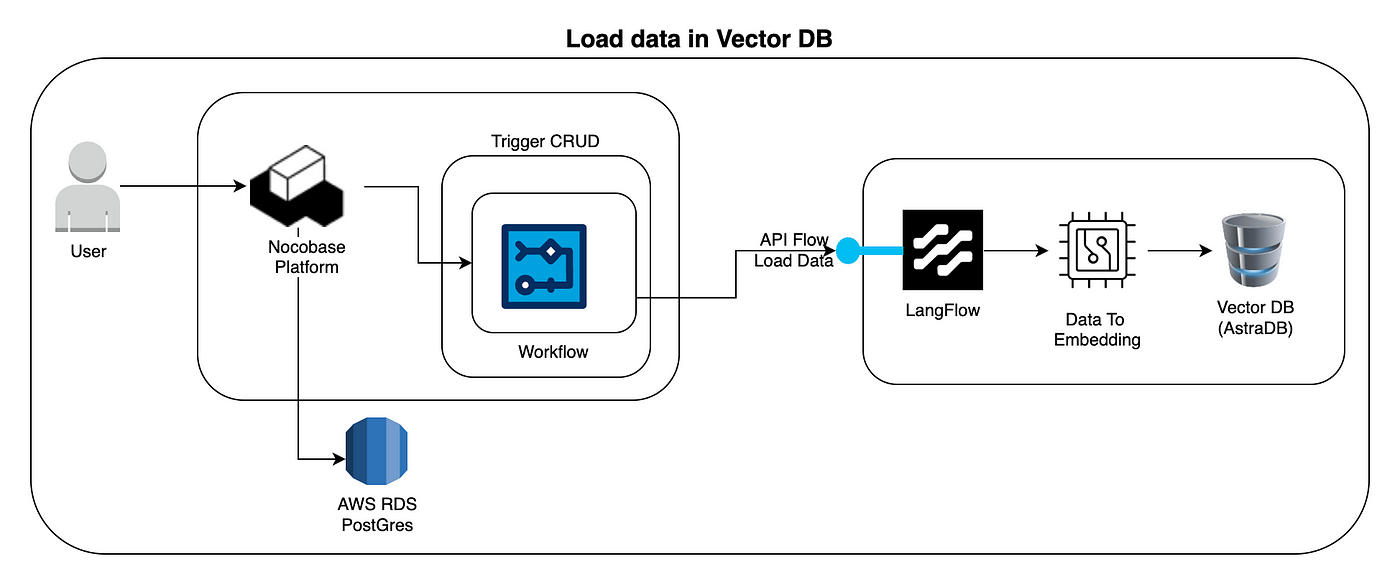
この図は、新しいデータ(または更新されたデータ)が 埋め込み(embeddings) に変換され、ベクトルデータベース に保存されるまでの流れを示しています。
- ユーザー → NocoBaseプラットフォーム ユーザーがNocoBaseプラットフォームとやり取りします(例:コレクションにレコードを追加または更新)。
- CRUD操作のトリガー NocoBase内のCRUD(作成、読み取り、更新、削除)操作がイベントまたは内部ワークフローをトリガーします。
- ワークフロー(NocoBase) NocoBaseには、データの変更に応答するように設定されたワークフローがあります。レコードの作成または変更を検出すると、次のステップを開始します。
- APIフロー:データの読み込み NocoBaseのワークフローは、LangFlowのAPIまたは外部サービスを呼び出して、埋め込みに変換されるデータを送信します。
- LangFlow — データから埋め込みへ LangFlowはデータを受け取り、言語モデルを使用してコンテンツをベクトル(埋め込み)に変換します。これらの埋め込みは、テキストの意味や文脈を数値的に表現し、セマンティック検索を可能にします。
- ベクトルデータベース(AstraDB) 埋め込みはベクトルデータベース(AstraDB)に保存され、各埋め込みは元のコンテンツ(例:ドキュメント、レコード、テキスト)に関連付けられます。
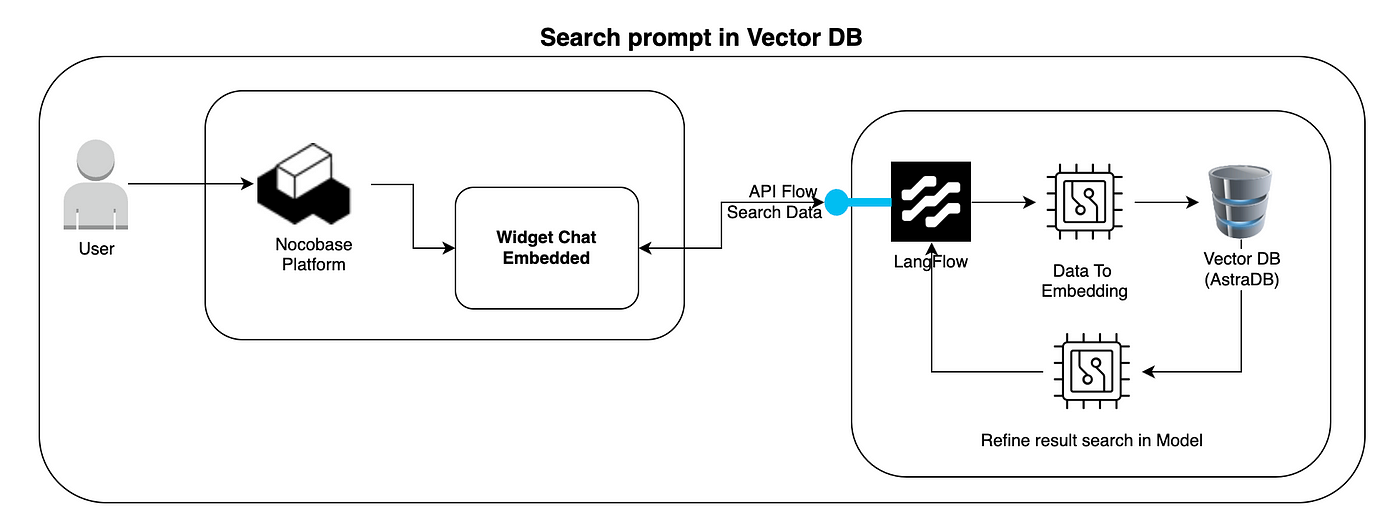
この図は、ユーザーがベクトルデータベースに対してセマンティッククエリを実行し、関連する結果を受け取る方法も示しています。
- ユーザー → NocoBaseプラットフォーム ユーザーは再びNocoBaseプラットフォームとやり取りしますが、今回は埋め込みチャットウィジェット(または他の検索インターフェース)を使用します。
- 埋め込みチャットウィジェット ユーザーは質問やプロンプトを入力します。例:「アプリケーションXに関する情報を表示してください。」 このウィジェットは、クエリを処理するためにLangFlowにリクエストを送信します。
- LangFlow — データから埋め込みへ LangFlowはユーザーのプロンプトを埋め込みに変換し、検索意図をベクトル形式で表現します。
- ベクトルデータベース(AstraDB)— 類似性検索 プロンプトの埋め込みを使用して、AstraDB内で最も類似したベクトル(つまり、意味的に最も近いコンテンツ)を検索します。
- モデルでの検索結果の精緻化 AstraDBから返された結果に基づいて、LangFlowはOpenAIモデル(または他のLLM)を使用して検索結果を精緻化します。
- ユーザーへの応答 最終的な結果(テキスト、ドキュメント、または生成された応答)がNocoBaseのチャットウィジェットに返され、ユーザーに表示されます。
NocoBaseを使用したアプリケーション
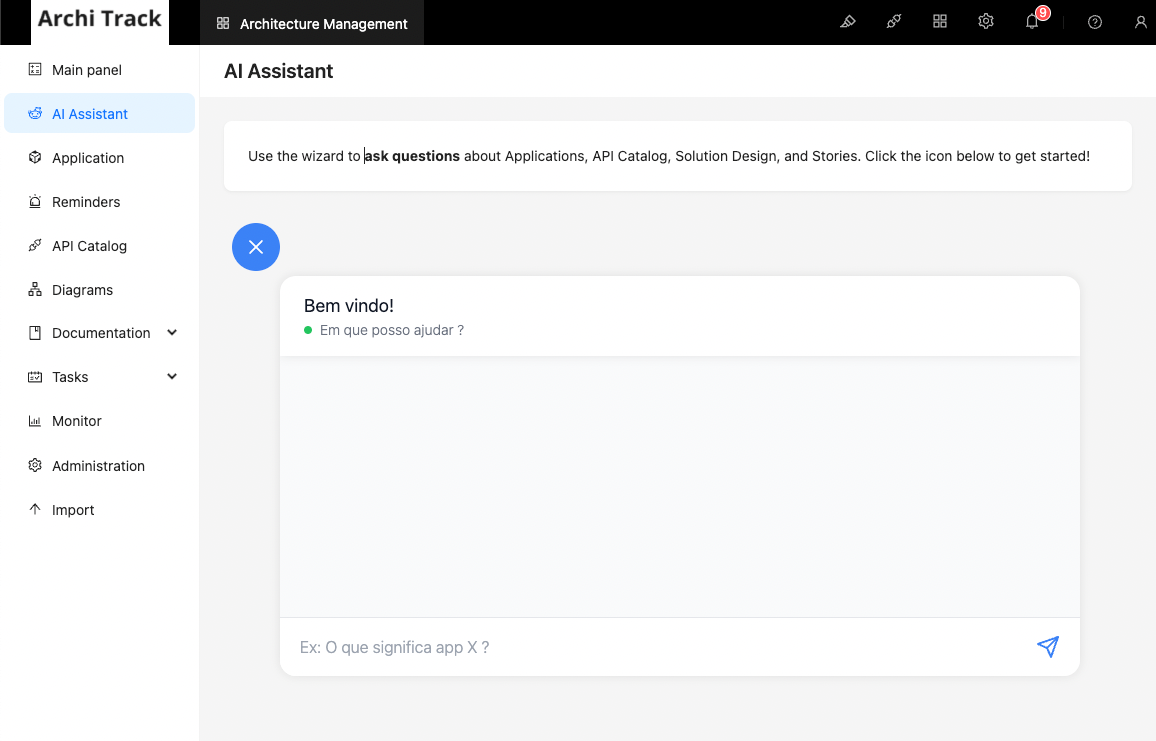
この記事では、以前に作成した同じアプリケーションを使用します。これはNocoBaseの機能を紹介するために開発されたアプリケーションで、AIアシスタントを実装します。以下は、アシスタントの動作を示す画像です。
アイデアは、質問を通じて機能に関する洞察を得ることです。利用可能な機能は次のとおりです:アプリケーション、APIカタログ、ソリューションデザイン、ストーリー。
LangFlowとAstraDBとは?
LangFlow は、ブラジルの開発者によって作成されたオープンソースツールで、言語モデルを含むワークフローを構築、視覚化、デバッグするためのグラフィカルインターフェースを提供します。LangChainエコシステムに基づいており、自然言語処理(NLP)パイプラインや生成AIアプリケーションをインタラクティブに作成することを容易にします。これにより、開発者はAPI呼び出し、テキスト変換、ビジネスロジックなどのさまざまなコンポーネントを接続できます。
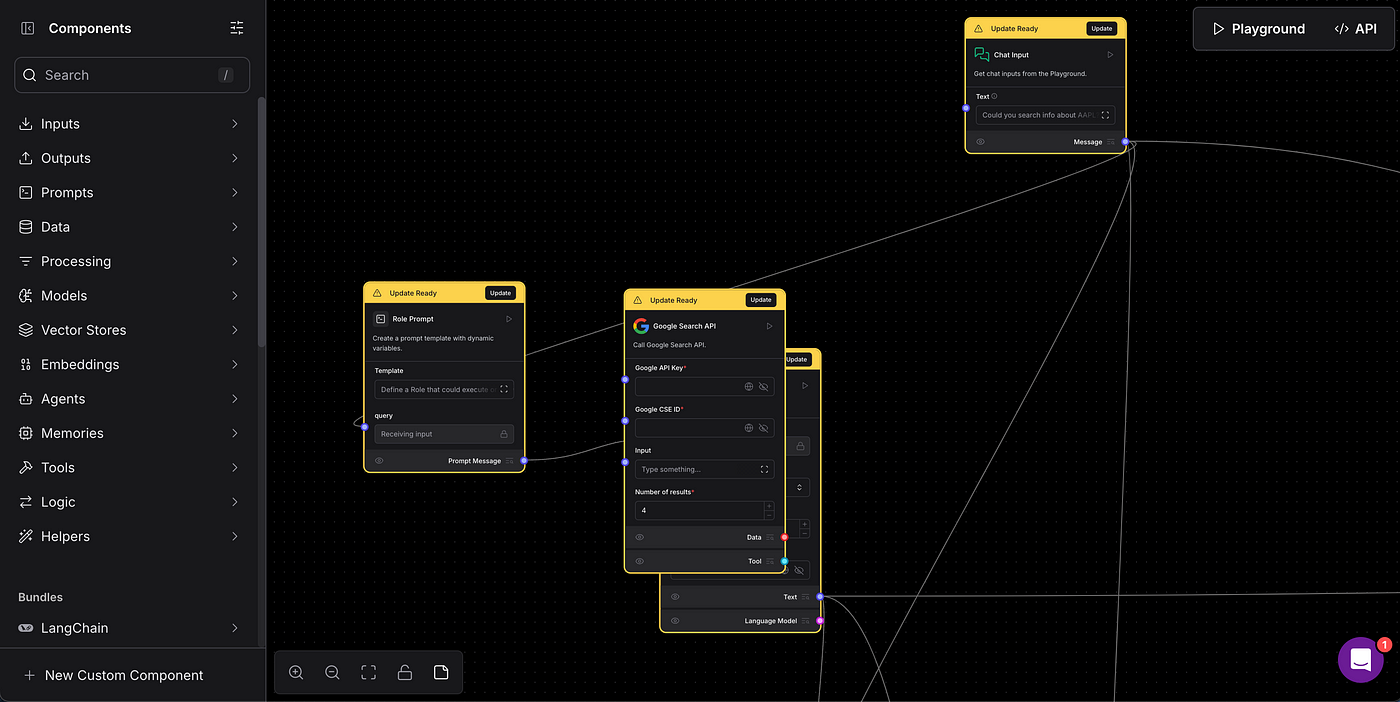
AstraDB は、もともとApache Cassandraに基づいた分散データベースサービスでしたが、非構造化データの保存とベクトル検索の機能を拡張しました。このベクトルデータベース機能は、機械学習アプリケーション、セマンティック検索、レコメンデーションシステム、および高次元データタスクに特に有用です。
LangFlowのインストール
Dockerを使用して LangFlow をインストールするには、以下のコマンドを実行し、localhost:7860 でシステムにアクセスします。
docker run -it --rm -p 7860:7860 langflowai/langflow:latest
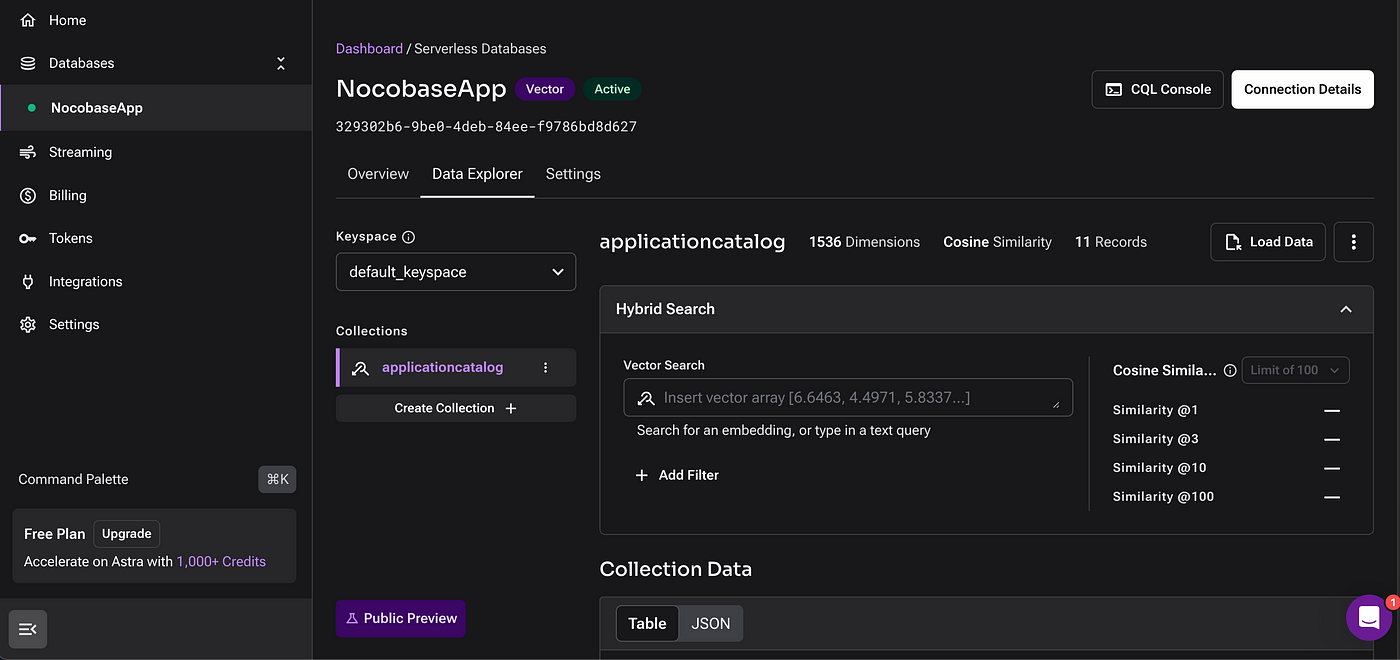
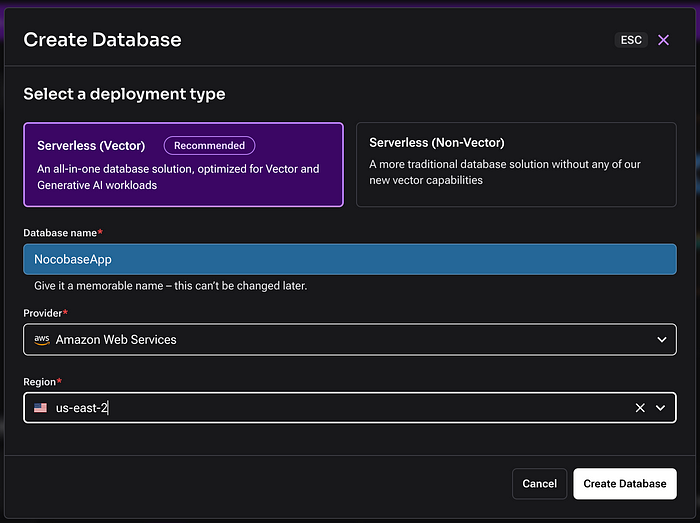
AstraDBの設定
AstraDBにアカウントを作成した後、以下のようにデータベースとコレクションを設定できます。
手順は非常に簡単です:
- プロバイダー を選択します。
- リージョン を選択します。
- データベース を作成します。
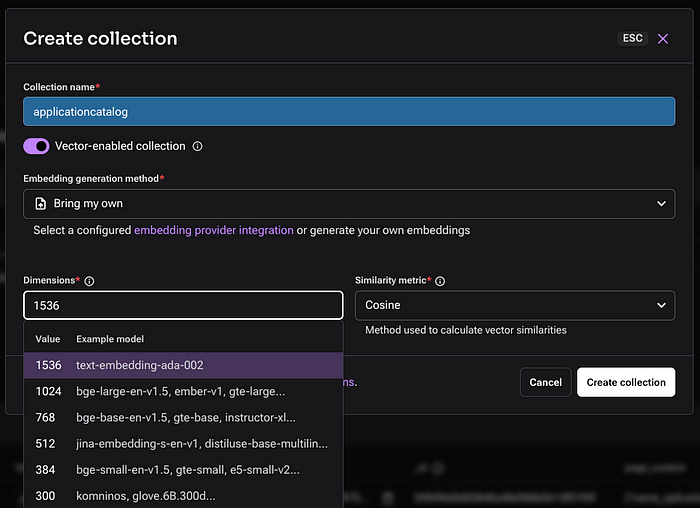
コレクションはベクトル化されたデータを保存するため、Embedding 機能を設定することが重要です。これは、データをベクトル化するLLMモデルに対応します。
OpenAI、Nvidia、Googleなど、さまざまなモデルが利用可能です。この記事では、データ変換に text-embedding-ada-002 モデルを使用します。
ベクトルデータベースへのデータ読み込み
このステップでは、検索対象のデータをベクトルデータベースに取り込みます。
- LangFlowのワークフローがURL経由でデータを受け取ります。
- テキストを処理します。
- text-embedding-ada-002 を使用してベクトル形式に変換します。
- 設定されたコレクションにAstraDBに保存します。
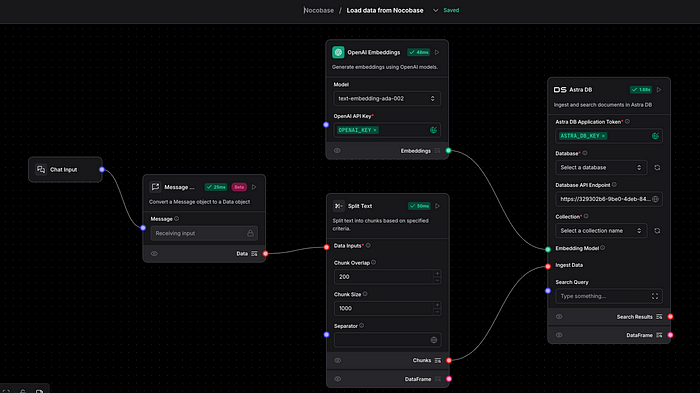
重要なポイント
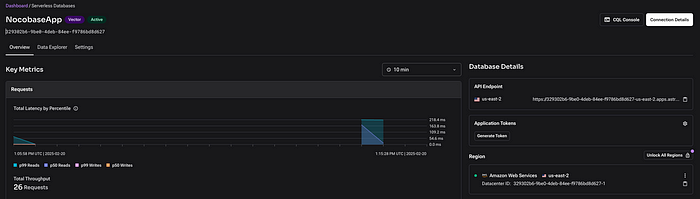
- データベース接続コンポーネントで AstraDB Token を定義する必要があります。トークンを生成するには、AstraDBのコレクションページで Generate Token をクリックします。
- ソースファイルはこの リポジトリ で見つけることができます。
- OpenAIモデルを使用するには、APIにクレジットを追加し、トークンを生成して埋め込み生成コンポーネントに設定する必要があります。詳細は このドキュメント を参照してください。
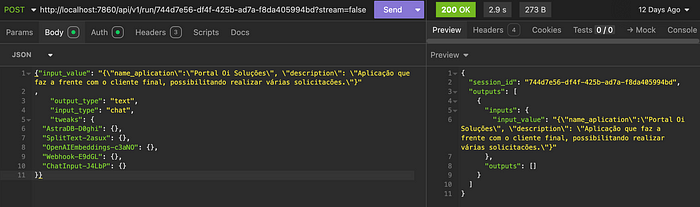
Postmanを使用して、LangFlowの API > cURL から取得したURLを呼び出すことでテストできます。以下はPostmanを使用したリクエストの例です。
モデルを使用した検索の実行
このステップでは、ベクトルデータベースからデータを取得し、RAG(Retrieval-Augmented Generation) を使用して結果を精緻化します。
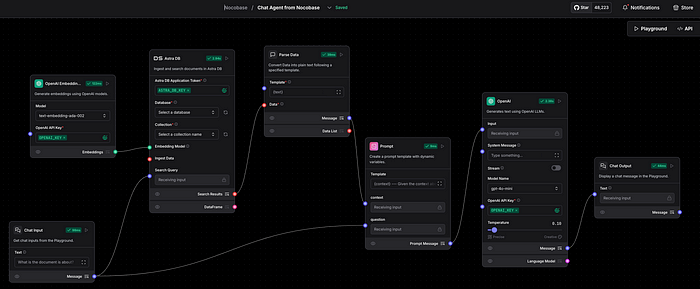
この段階でも、OpenAIとAstraDBのトークンをそれぞれのコンポーネントに定義する必要があります。ソースファイルはこの リポジトリ で見つけることができます。
テストするには、LangFlow内の Playground タブで利用可能なチャットを使用します。
NocoBaseでのワークフローの設定
このステップでは、ベクトル化が必要なデータを送信するためのトリガーをアプリケーションに作成します。つまり、新しいデータが挿入されるたびに、LangFlow APIに送信して処理します。
これを実現するために、NocoBaseの ワークフロー 機能を使用します。ワークフローの詳細については、このリンク を参照してください。
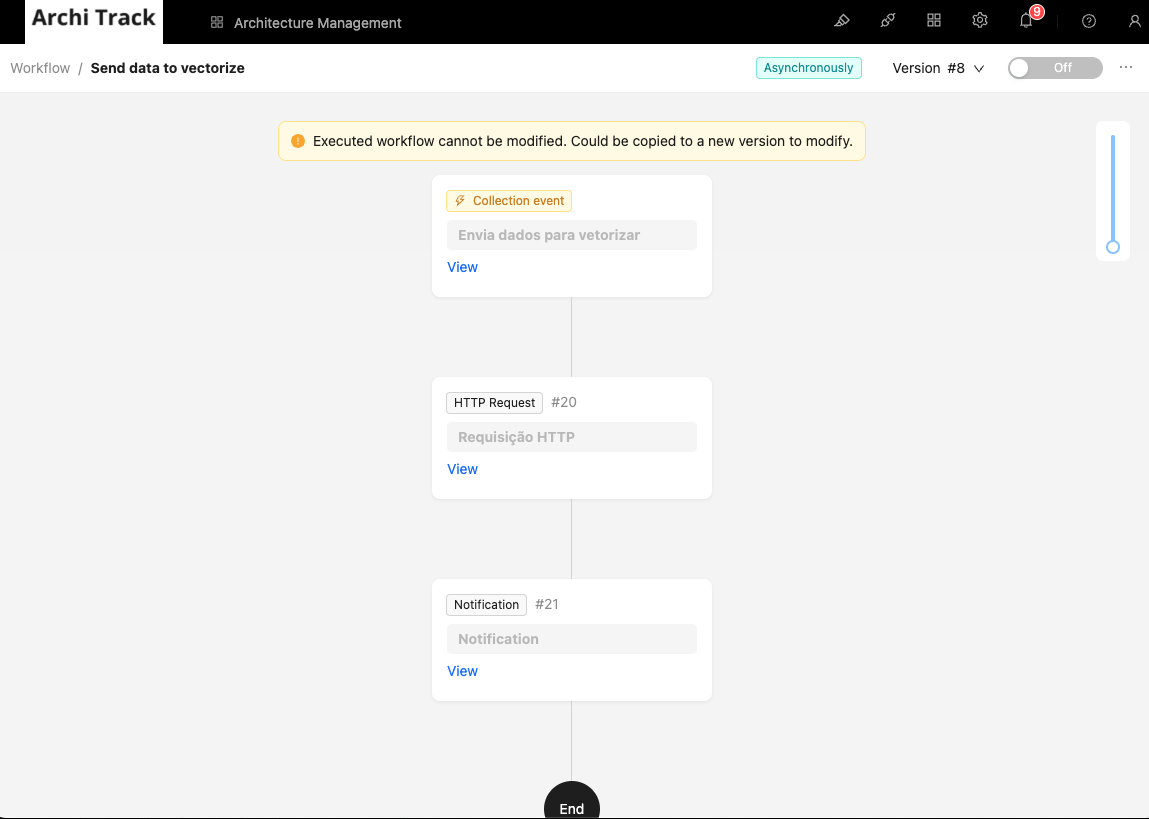
アプリケーションのコレクションからベクトル化されたコレクションにデータを送信するワークフローを作成します。
手順:
- 新しいワークフローを作成し、コレクションイベント を選択します。
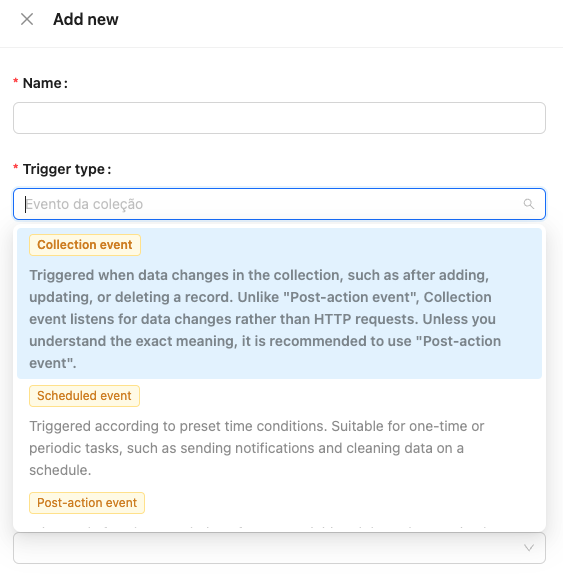
- トリガー を アプリケーション コレクションへの挿入として定義します。
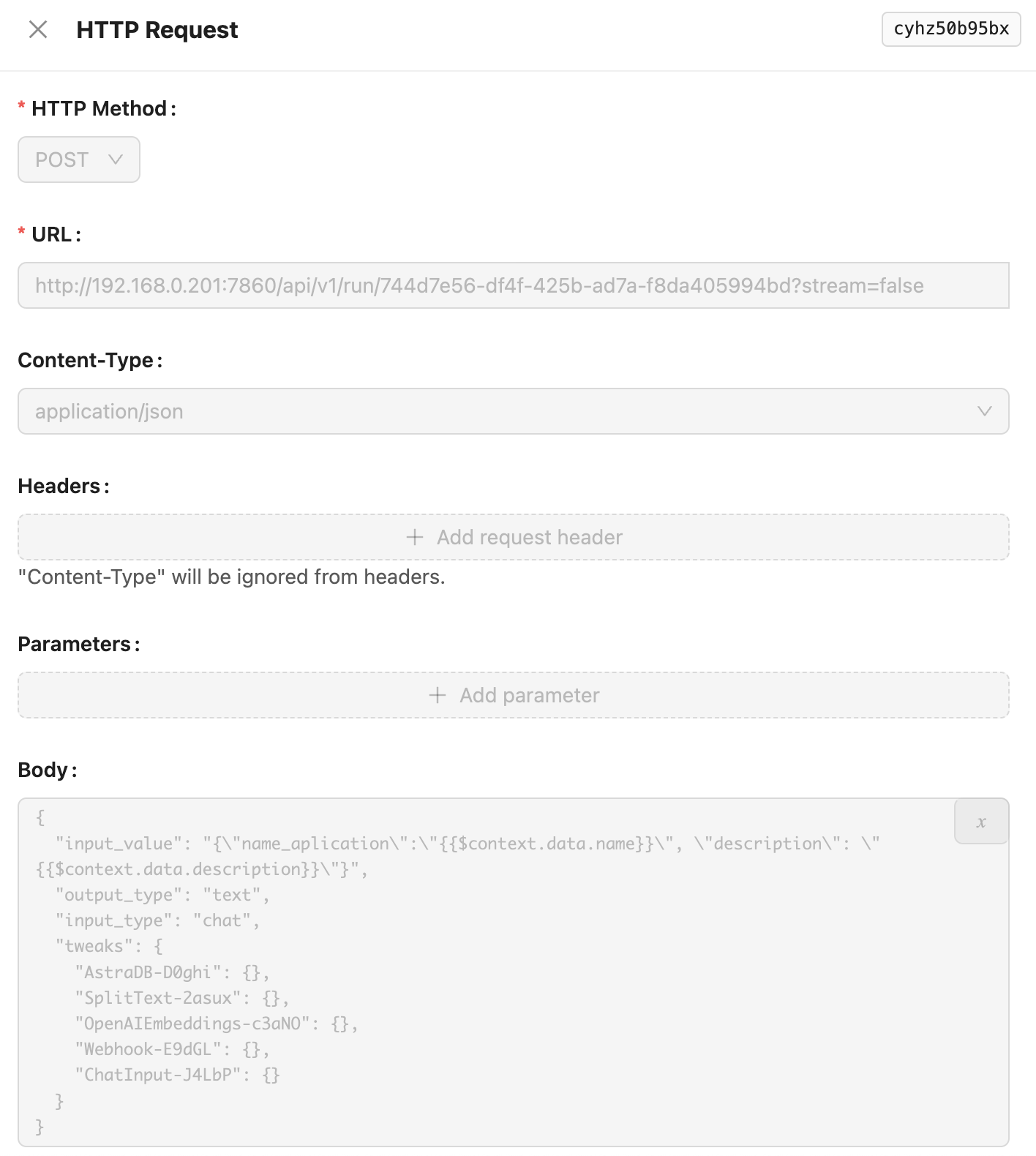
- アプリケーションのデータをベクトル化するために送信する リクエストノード を作成します。この記事では タイトル と 説明 を例としますが、ビジネスルールに従っていかなる情報も送信できます。
- 通知ステップ はオプションで、実行する必要はありません。
NocoBaseにチャットウィジェットを追加
まず、LangFlowにアクセスし、API オプションからチャットウィジェットのコードをコピーします。以下の画像を参照してください。
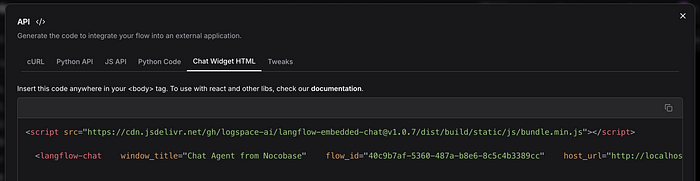
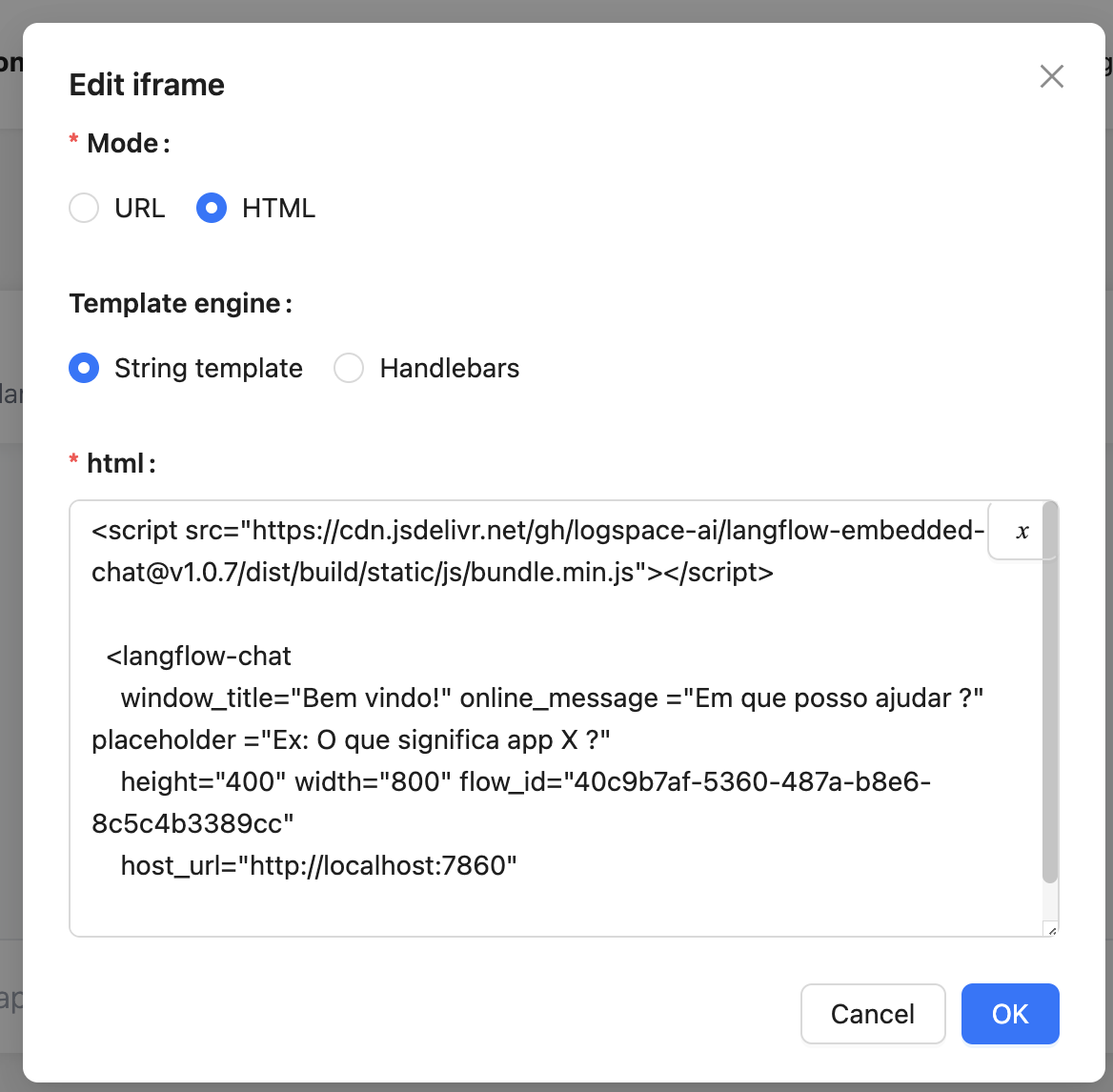
次に、ページを作成し、iframeコンポーネントを追加します。このコンポーネントの詳細については、このリンク を参照してください。
設定:
- モード: HTML
- HTML: 以下のコードを使用し、flow_id と host_url をLangFlowの値に置き換えます。
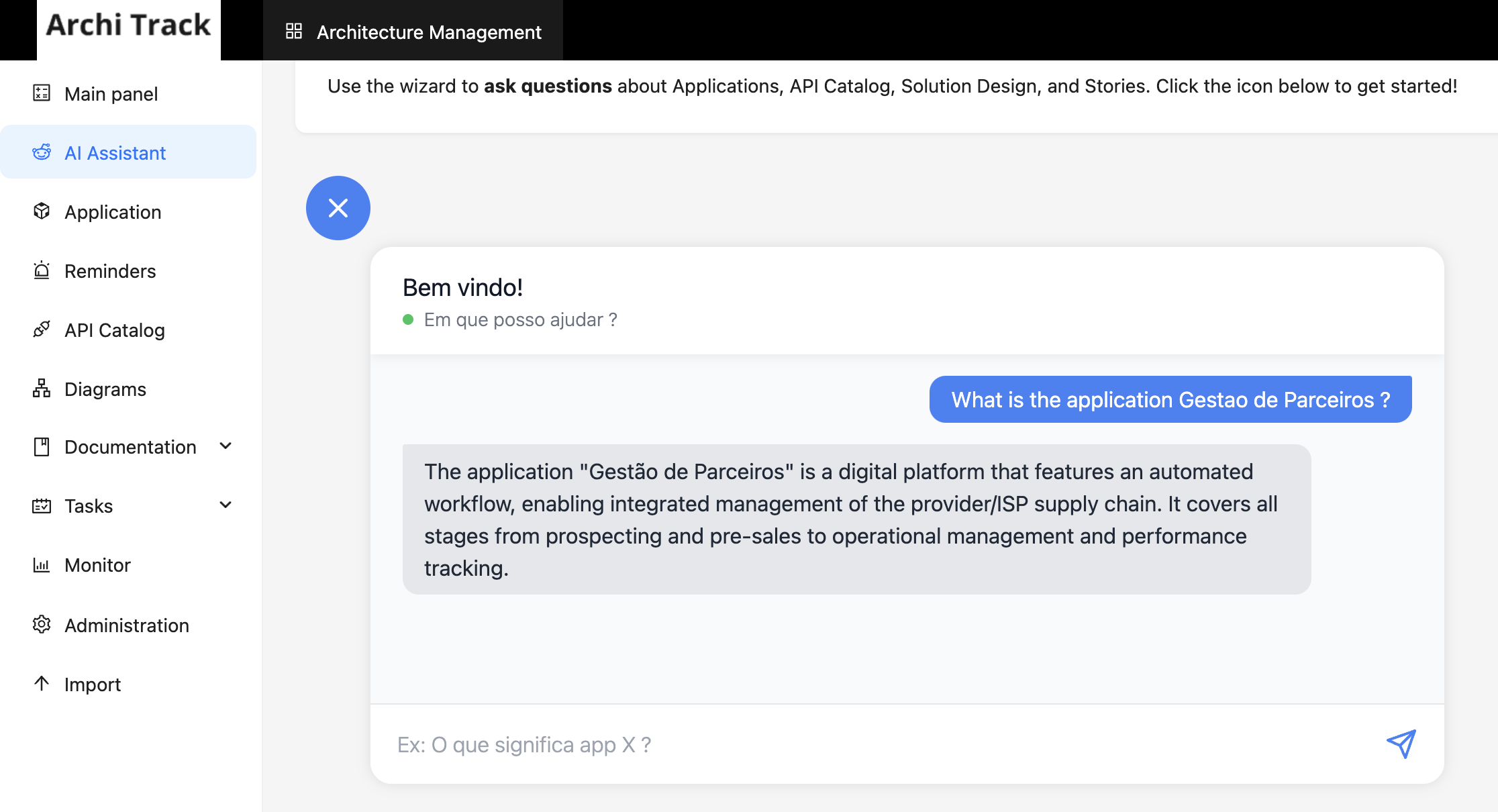
チャットのテスト
作成したメニューに戻り、アシスタントをテストして応答を確認します。以下の例を参照してください。
結論
この記事では、NocoBase、LangFlow、AstraDBを統合したAIアシスタントの作成方法を紹介し、データのベクトル化とインテリジェントな検索を実現しました。
このアプローチにより、登録されたデータから価値ある洞察を生成できるアシスタントを実装し、RAG(Retrieval-Augmented Generation) 技術を使用して検索結果を精緻化しました。
これはこのアーキテクチャが提供できるものの始まりに過ぎません。小さな調整を加えることで、機能を拡張し、新しいAIモデルを統合し、ユーザーエクスペリエンスを向上させることができます。🚀
関連文献: