
在大数据时代,企业和组织面临着海量的数据挑战。随着应用程序复杂性的提高以及用户需求不断演变,开发团队需要高效地处理大量数据,以便快速做出决策。然而,在众多信息中,如何识别并有效利用那些对决策至关重要的数据呢?
数据管理工具提供了解决方案,帮助开发团队从繁杂的信息中提取价值,优化数据结构,使有效数据得到更好的应用。
在这篇全面指南中,我们将探讨数据管理工具的基本概念、关键步骤、重要性,以及如何选择适合自身需求的数据管理工具。希望能够帮助你的团队高效利用数据管理工具,充分挖掘数据价值,实现数据驱动的成功转型!
什么是数据管理?
数据管理是指对数据进行有效组织和维护的过程,涵盖了数据的提取、清洗、整合和加载(ETL)。这一过程通常发生在数据存储、数据分析和数据可视化的各个环节。数据管理的目的是提升数据的质量和可用性,使其适合于不同的分析需求和应用场景。
数据管理的关键步骤
- 数据提取:从不同的数据源(如数据库、API、文件系统等)提取数据。
- 数据清洗:去除重复数据、填补缺失值、纠正数据格式和处理异常值。
- 数据整合:将来自不同来源的数据合并,以便统一分析。
- 数据转换:将数据格式转换为所需的形式,例如将 CSV 转为 JSON,或将关系型数据转为 NoSQL 格式。
- 数据加载:将转换后的数据加载到目标系统或数据仓库中,以供后续使用。
数据管理的重要性
数据管理对于企业的重要性体现在多个方面:
- 提高数据质量:清洗和整合数据可以提升数据的准确性和一致性。
- 增强数据可访问性:将数据格式化为适合分析的形式,使数据更易于访问和使用。
- 支持业务决策:高质量的数据能够支持更深入的分析,从而为决策提供有力依据。
- 满足合规要求:通过数据转换,企业能够确保数据符合行业法规和标准。
数据管理工具的选择标准
在选择合适的数据管理工具时,开发者和团队需考虑多个关键因素,其中开源和自托管的特性尤为重要:
- 开源:开源工具可根据特定需求进行修改和优化,适应独特的业务流程,同时,活跃的开源社区为工具的持续改进和问题解决提供支持。
- 自托管:自托管能力使用户能在自己的服务器上运行工具,增强数据安全性和隐私保护,同时提高控制和灵活性,以符合 IT 基础设施和安全政策。
- 功能:工具是否支持多种数据源和格式,以满足具体的数据转换需求。
- 性能:在处理大规模数据时的效率和稳定性。
- 易用性:用户界面是否友好,学习曲线是否适合团队成员的技术背景。
- 社区和支持:是否拥有活跃的社区和良好的技术支持,方便获取帮助和资源。
- 价格:工具的成本是否符合预算,包括潜在的维护和扩展费用。
推荐的开源自托管数据管理工具
NocoBase
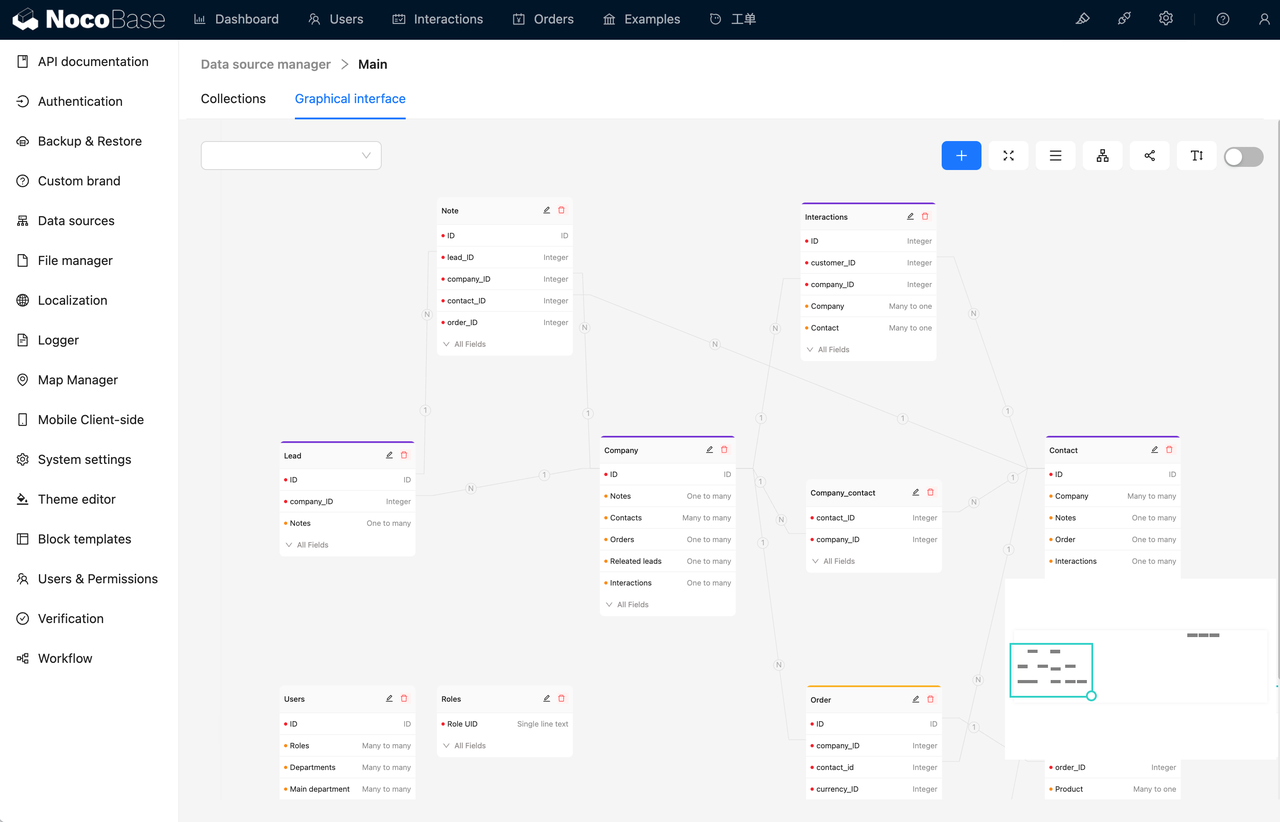
概述
GitHub:https://github.com/nocobase/nocobase
NocoBase 是一个开源无代码/低代码开发平台,通过高效的数据集成能力,能够将分散在不同来源的数据统一整合,同时其自动化数据清洗能力,能够显著降低数据治理成本,帮助用户快速构建定制化解决方案,提升工作效率。
🙌 上手实践:NocoBase 实战教程 —— 任务管理系统
💡 推荐阅读:美航通过 NocoBase 节省了 70% 的物流系统升级成本
特点
- 所见即所得界面:通过可视化界面和简单的逻辑,用户可以轻松创建数据转换流程。
- 插件化架构:支持用户根据需求定制和扩展功能,可以通过插件实现个性化数据处理。
- 支持多种数据源:兼容多种数据源,支持数据库、API 等不同格式的数据,满足各种应用场景的需求。
优缺点
- 优点:易于使用,适合不具备深厚技术背景的用户。
- 缺点:功能可能不如一些更复杂的工具丰富。
价格:提供免费的社区版本和更专业的商业版本。
Nifi
概述
GitHub:https://github.com/apache/nifi
Nifi 是一个强大的数据流管理工具,支持数据的自动化流动和转换。它以可视化界面著称,使用户能够轻松设计数据流。
特点
- 图形化用户界面:通过拖放、连接不同的处理器来构建数据处理流程,无需编写复杂的代码。
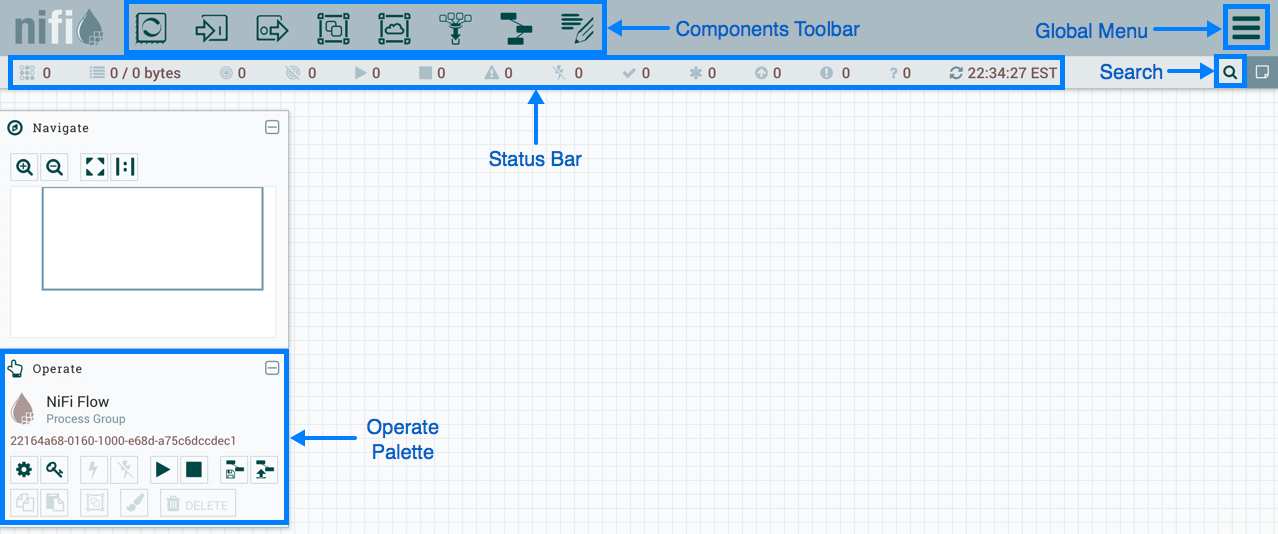
- 安全的数据处理:NiFi 提供了多种安全机制,包括用户认证、授权和数据加密等,以确保数据的安全性和隐私性。
- 丰富的连接器:支持多种数据源和目标,包括数据库、文件和 API。
优缺点
- 优点:灵活性高,适合各种数据处理需求。
- 缺点:对于复杂场景,可能需要较高的学习曲线。
价格:开源,免费使用。
Airflow

概述
GitHub:https://github.com/apache/airflow
Airflow 是一个开源工作流管理平台,主要用于编排复杂的数据处理和转换任务。
💡 阅读更多:⭐️ GitHub Star 数量前十的工作流项目
特点
- 灵活的调度:工作流参数化是利用 Jinja 模板引擎构建,能够适应各种复杂的调度需求。
- 可扩展性:可以轻松定义运算符,所有组件都可扩展,能够轻松集成到不同的系统中。
- Python脚本:使用标准 Python 功能创建工作流,包括用于计划的日期时间格式和用于动态生成任务的循环。
优缺点
- 优点:强大的调度和监控功能。
- 缺点:需要一定的开发经验来配置和使用。
价格:开源,免费使用。
Pentaho
概述
GitHub:https://github.com/pentaho/pentaho-kettle
Pentaho 是一款开源的ETL工具,广泛用于数据转换、清洗和加载。
特点
- 拖放式界面:用户可以通过可视化方式设计数据流程,降低了数据集成的难度。
- 支持多种数据源:与关系型数据库、NoSQL 和文件系统兼容。
- 丰富的插件支持:支持插件扩展,用户可以根据自己的需求开发新的插件。
优缺点
- 优点:易于使用且功能全面。
- 缺点:某些高级功能需要额外配置和开发。
价格:提供免费版和付费的商业版。
Singer

概述
GitHub:https://github.com/singer-io
Singer 是一个开源的标准化数据提取和加载工具,适用于创建可重用的 ETL 管道。
特点
- 模块化设计:使用 “tap” 和 “target” 来定义数据流,便于扩展。

- 灵活性高:支持多种数据源和目标,适合构建定制化的解决方案。
- 基于 JSON:Singer 应用程序与 JSON 相连,易于使用且可以用任何编程语言实现。
优缺点
- 优点:灵活性强,适合构建个性化的数据管道。
- 缺点:需要一定的技术背景来配置和使用。
价格:开源,免费使用。
Spark

概述
GitHub:https://github.com/apache/spark
Spark 是一个统一的分析引擎,适用于大规模数据处理和转换,支持批处理和流处理。
特点
- 批处理/流式处理数据:使用用户的首选语言(Python、SQL、Scala、Java 或 R)以批处理和实时流式处理的方式统一数据处理。
- SQL 分析:执行快速、分布式的 ANSI SQL 查询,用于仪表板和临时报告。
- 丰富的生态系统:与大数据、机器学习等工具兼容。

优缺点
- 优点:强大的性能和灵活性,适合各种数据处理场景。
- 缺点:对新手来说,学习曲线较陡。
价格:开源,免费使用。
总结
- NocoBase:所见即所得的界面和灵活的插件架构简化了数据集成的复杂性。
- Nifi:图形化界面和安全机制确保高效安全的数据流动。
- Airflow:灵活调度和可扩展性提升了复杂任务的编排效率。
- Pentaho:拖放式设计和丰富插件支持降低了学习门槛。
- Singer:模块化设计与灵活性便于构建可重用的 ETL 管道。
- Spark:统一的批处理与流处理能力,满足大规模数据处理需求。
😊 希望这篇指南能帮助你选择合适的数据管理工具,提高数据处理效率,实现数据驱动的业务增长。
相关阅读: